R Bloggers Bulk Upload to Redshift ?
Redshift has emerged as a popular completely managed data warehousing service offered by Amazon. Redshift offers a very flexible pay-as-you-use pricing model, which allows the customers to pay for the storage and the instance blazon they utilize. Increasingly, more and more businesses are choosing to adopt Redshift for their warehousing needs. In this weblog, we talk over one of the key aspects of building your Redshift data warehouse: loading information to Redshift.
Table of Contents
- What is Amazon Redshift?
- Methods for Loading Data to Redshift
- Method 1: Loading Information to Redshift using the Copy Command
- Method ii: Loading Data to Redshift using the Insert Into Command
- Method iii: Loading Information to Redshift using AWS Services
- Method iv: Using Hevo Information, a No-code Data Pipeline
- Conclusion
What is Amazon Redshift?

Redshift's biggest advantage is its ability to run complex queries over millions of rows and return ultra quick results. The querying layer is implemented based on the PostgreSQL standard. This is made possible by Redshift's massively parallel processing architecture which uses a collection of compute instances for storage and processing. Redshift enables the customers to choose amidst different types of instances co-ordinate to their budget and whether they have a storage-intensive use instance or a compute-intensive employ case. Redshift'due south dumbo compute instances have SSDs and the dense storage instances come with HDDs. A detailed article on Redshift pricing can be found hither .
In Redshift's massively parallel processing architecture, one of the instances is designated as a leader node. Other nodes are known as compute nodes and are responsible for actually executing the queries. Leader nodes handle the customer communication, prepared query execution plans and assign work to the compute nodes co-ordinate to the slices of information they handle. A detailed explanation of Redshift architecture can exist found here .
Redshift tin can scale seamlessly by calculation more nodes, upgrading nodes or both. The limit of Redshift scaling is stock-still at 2PB of data. The latest generation of Redshift nodes is capable of reducing the scaling downtimes to a few minutes. Redshift offers a feature chosen concurrency scaling which tin scale the instances automatically during high load times while adhering to the budget and resource limits predefined by customers.
Concurrency scaling is priced separately, but users are provided with a free hour of concurrent scaling for every 24 hours a Redshift cluster stays operational. Redshift Spectrum is another unique feature offered by AWS, which allows the customers to employ simply the processing capability of Redshift. The data, in this example, is stored in AWS S3 and not included equally Redshift tables.
Key Features of Amazon Redshift
The key features of Amazon Redshift are every bit follows:
- Massively Parallel Processing
- Fault Tolerance
- Redshift ML
- Column-oriented Design
ane) Massively Parallel Processing (MPP)
Massively Parallel Processing (MPP) is a distributed pattern approach in which the divide and conquer strategy is applied by several processors to large data jobs. A large processing chore is broken down into smaller jobs which are then distributed amidst a cluster of Compute Nodes. These Nodes perform their computations parallelly rather than sequentially. As a result, at that place is a considerable reduction in the corporeality of time Redshift requires to consummate a unmarried, massive job.
2) Error Tolerance
Data Accessibility and Reliability are of paramount importance for any user of a database or a Data Warehouse. Amazon Redshift monitors its Clusters and Nodes around the clock. When whatever Node or Cluster fails, Amazon Redshift automatically replicates all data to healthy Nodes or Clusters.
3) Redshift ML
Amazon Redshift houses a functionality called Redshift ML that gives data analysts and database developers the power to create, railroad train and deploy Amazon SageMaker models using SQL seamlessly.
iv) Column-Oriented Design
Amazon Redshift is a Column-oriented Data Warehouse. This makes it a simple and cost-effective solution for businesses to analyze all their data using their existing Business Intelligence tools. Amazon Redshift achieves optimum query performance and efficient storage past leveraging Massively Parallel Processing (MPP), Columnar Data Storage, along with efficient and targeted Data Pinch Encoding schemes.
Method 1: Loading Data to Redshift using the Re-create Control
The Redshift Copy Command is one of the most popular ways of importing data into Redshift and supports loading data of various formats such as CSV, JSON, AVRO, etc. This method makes use of DynamoDB, S3, or the EMR cluster to facilitate the information load process and works well with bulk data loads.
Method 2: Loading Information to Redshift using the Insert Into Command
This method makes use of the Redshift Insert Into Command. The Insert Into Control is based on PostgreSQL and allows users to insert unmarried or multiple records of information into their Redshift tables. It requires users to write queries to insert data equally per their requirements.
Method 3: Loading Information to Redshift using AWS Services
Using diverse utilities provided by Amazon Web Service to load data into Redshift is one such way. AWS supports bringing in data from a diverseness of sources and transferring information technology, either by using the AWS data pipeline or AWS Glue, an ETL tool, which makes use of the copy and the unload control.
Method four: Loading Information to Redshift Using Hevo's no code data pipeline
Hevo Data, an Automated No-code Information Pipeline, helps you load data to Amazon Redshift in real-time and provides you with a hassle-gratis experience. You can easily ingest data using Hevo's Information Pipelines and replicate information technology to your Redshift warehouse without writing a unmarried line of lawmaking. Hevo's end-to-endData Management service automates the process of not only loading information from your sources but also transforming and enriching information technology into an analysis-prepare form when it reaches Redshift.
Hevo supports straight integrations of 100+ sources(including 40 gratuitous sources) and its Data Mapping feature works continuously to replicate your information to Redshift and builds a unmarried source of truth for your business. Hevo takes full charge of the information transfer process, assuasive you to focus your resources and time on other key concern activities.
Methods for Loading Data to Redshift
Redshift provides multiple ways of loading data from various sources. On a wide level, data loading mechanisms to Redshift can be categorized into the beneath methods:
- Method 1: Loading Data to Redshift using the Copy Command
- Method 2: Loading Data to Redshift using the Insert Into Command
- Method 3: Loading Data to Redshift using AWS Services
- Method iv: Using Hevo Data, a No-lawmaking Information Pipeline
Method 1: Loading Information to Redshift using the Copy Command
The redshift Re-create command is the standard way of loading bulk data TO Redshift. COPY command can apply the following sources for loading data.
- DynamoDB
- Amazon S3 storage
- Amazon EMR cluster
Other than specifying the locations of the files from where data has to be fetched, the COPY control can also use manifest files which have a listing of file locations. Information technology is recommended to apply this approach since the Re-create command supports the parallel operation and copying a list of small files will be faster than copying a large file. This is because, while loading data from multiple files, the workload is distributed amidst the nodes in the cluster.


Download the Cheatsheet on How to Set Up High-functioning ETL to Redshift
Acquire the best practices and considerations for setting up high-performance ETL to Redshift
Re-create command accepts several input file formats including CSV, JSON, AVRO, etc.
It is possible to provide a column mapping file to configure which columns in the input files get written to specific Redshift columns.
Re-create command also has configurations to uncomplicated implicit data conversions. If naught is specified the data types are converted automatically to Redshift target tables' information type.
The simplest Copy command for loading data from an S3 location to a Redshift target table named product_tgt1 will be as follows. A redshift table should be created beforehand for this to piece of work.
re-create product_tgt1 from 's3://productdata/product_tgt/product_tgt1.txt' iam_role 'arn:aws:iam::<aws-business relationship-id>:function/<role-name>' region 'usa-east-2'; A detailed explanation of how to use the Re-create command is available here .
Method ii: Loading Data to Redshift using Insert Into Command
Redshift's INSERT INTO command is implemented based on the PostgreSQL. The simplest case of the INSERT INTO command for inserting iv values into a tabular array named employee_records is every bit follows.
INSERT INTO employee_records(emp_id,section,designation,category) values(ane,'admin','banana','contract'); It can perform insertions based on the post-obit input records.
- The above code snippet is an case of inserting single row input records with column names specified with the command. This means the column values have to be in the aforementioned guild equally the provided cavalcade names.
- An alternative to this command is the single row input tape without specifying column names. In this instance, the cavalcade values are always inserted into the get-go n columns.
- INSERT INTO command also supports multi-row inserts. The column values are provided with a list of records.
- This control can also be used to insert rows based on a query. In that case, the query should return the values to be inserted into the exact columns in the same guild specified in the command.
A detailed annotation on the Redshift INSERT INTO command is available here .
Fifty-fifty though the INSERT INTO control is very flexible, it tin can atomic number 82 to surprising errors considering of the implicit data blazon conversions. This control is as well non suitable for the bulk insert of data.
Method 3: Loading Data to Redshift using AWS Services
AWS provides a set of utilities for loading information from different sources to Redshift. AWS Gum and AWS Data pipeline are two of the easiest to use services for loading data from AWS table.
AWS Information Pipeline
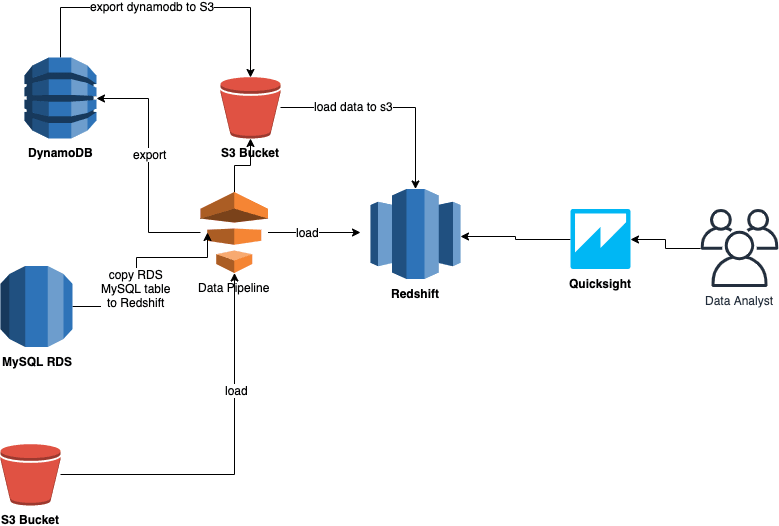
AWS data pipeline is a web service that offers extraction, transformation, and loading of data as a service. The ability of the AWS data pipeline comes from Amazon's elastic map-reduce platform. This relieves the users of the headache to implement a complex ETL framework and helps them focus on the actual business logic.
AWS Data pipeline offers a template activity chosen RedshiftCopyActivity that can be used to copy data from different kinds of sources to Redshift. RedshiftCopyActivity helps to copy data from the following sources.
- Amazon RDS
- Amazon EMR
- Amazon S3 storage
RedshiftCopyActivity has different insert modes – KEEP EXISTING, OVERWRITE EXISTING, TRUNCATE, Suspend.
KEEP EXISTING and OVERWRITE EXISTING considers the master key and sort keys of Redshift and allows users to control whether to overwrite or keep the current rows if rows with the same primary keys are detected.
A detailed explanation of how to use the AWS Data pipeline can exist found here.
AWS Glue
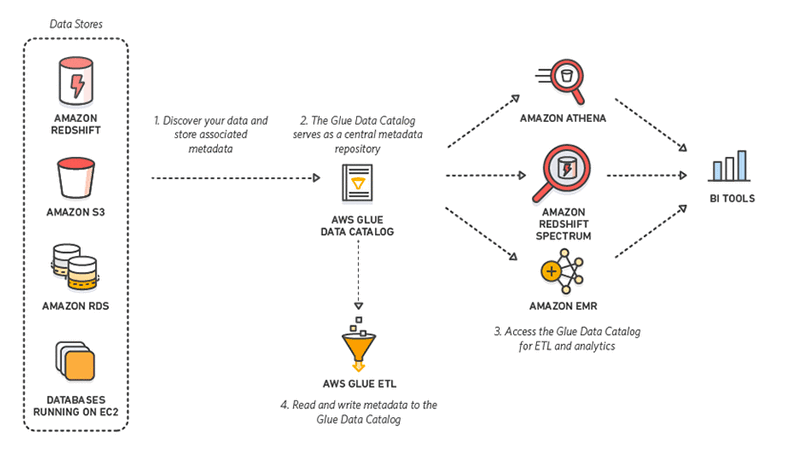
AWS Mucilage is an ETL tool offered as a service by Amazon that uses an rubberband spark backend to execute the jobs. Glue has the ability to discover new data whenever they come to the AWS ecosystem and store the metadata in catalogue tables.
Internally Glue uses the COPY and UNLOAD command to attain copying data to Redshift. For executing a copying operation, users need to write a glue script in its own domain-specific language.
Mucilage works based on dynamic frames. Before executing the copy activity, users need to create a dynamic frame from the data source. Assuming data is present in S3, this is done as follows.
connection_options = {"paths": [ "s3://product_data/products_1", "s3://product_data/products_2"]} df = glueContext.create_dynamic_frame_from_options("s3_source", connection-options) The above command creates a dynamic frame from two S3 locations. This dynamic frame can and then be used to execute a copy operation every bit follows.
connection_options = { "dbtable": "redshift-target-tabular array", "database": "redshift-target-database", "aws_iam_role": "arn:aws:iam::account-id:part/role-name" } glueContext.write_dynamic_frame.from_jdbc_conf( frame = s3_source, catalog_connection = "redshift-connection-name", connection_options = connection-options, redshift_tmp_dir = args["TempDir"]) The above method of writing custom scripts may seem a bit overwhelming at first. Glue can also auto-generate these scripts based on a web UI if the higher up configurations are known. Yous can read more about Glue here.
Method 4: Loading Data to Redshift Using Hevo'southward no code data pipeline
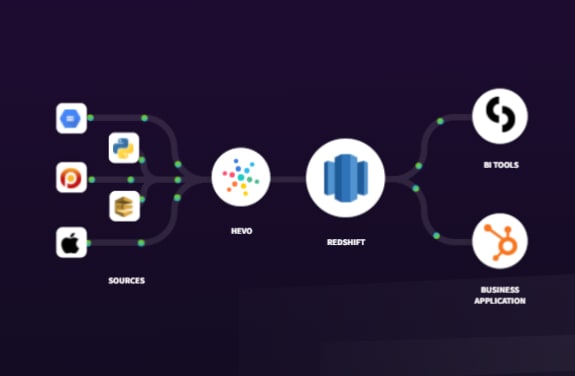
Hevo Data, an Automated No Code Data Pipeline tin help you motion data from 100+ sources swiftly to Redshift. You tin can gear up the Redshift Destination on the wing, as office of the Pipeline creation process, or independently. The ingested data is first staged in Hevo'due south S3 bucket before it is batched and loaded to the Amazon Redshift Destination.
Hevo'due south error-tolerant architecture will enrich and transform your information in a secure and consistent manner and load information technology to Redshift without any assistance from your side. You tin can entrust us with your data transfer process and enjoy a hassle-free experience. This fashion, y'all can focus more on Information Analysis, instead of data consolidation.
Hevo Data focuses on ii elementary steps to get you lot started:
- Authenticate Source: Connect Hevo Data with your desired data source in just a few clicks. You can choose from a multifariousness of sources such as MongoDB, JIRA, Salesforce, Zendesk, Marketo, Google Analytics, Google Drive, etc., and a lot more.
- Configure Destination: Load data from your desired data source to Redshift past merely providing your Redshift database credentials. Enter a name for your database, the host, and the port number for your Redshift database, and connect in a matter of minutes.
Hither are more than reasons to try Hevo:
- Secure: Hevo has a error-tolerant compages that ensures that your data is handled in a secure, consequent manner with zilch data loss.
- Schema Direction: Hevo takes away the tedious chore of schema management & automatically detects the schema of incoming data and maps information technology to yourRedshift schema.
- Quick Setup: Hevo with its automatic features, tin can be prepare in minimal fourth dimension. Moreover, with its simple and interactive UI, information technology is extremely like shooting fish in a barrel for new customers to work on and perform operations.
- Transformations: Hevo provides preload transformations through Python code. It also allows you to run transformation code for each upshot in the Data Pipelines you set up. You lot demand to edit the event object'south backdrop received in the transform method equally a parameter to conduct out the transformation. Hevo also offers elevate and drop transformations like Appointment and Control Functions, JSON, and Event Manipulation to proper name a few. These tin can exist configured and tested before putting them to use for assemblage.
- Minimal Learning: Hevo, with its simple and interactive UI, is extremely elementary for new customers to work on and perform operations.
- Hevo Is Congenital To Scale: As the number of sources and the book of your data grows, Hevo scales horizontally, handling millions of records per minute with very lilliputian latency.
- Incremental Information Load: Hevo allows the transfer of information that has been modified in existent-fourth dimension. This ensures efficient utilization of bandwidth on both ends.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
- Live Monitoring: Hevo allows you lot to monitor the data menses and check where your information is at a detail point in time.
With continuous Real-Fourth dimension data movement, Hevo allows yous to assemble data from multiple data sources and seamlessly load it to Redshift with a no-code, easy-to-setup interface. Try our 14-twenty-four hour period full-feature access free trial!
Get Started with Hevo for Free
Conclusion
The above sections particular different ways of copying data to Redshift. The first two methods of COPY and INSERT INTO command use Redshift's native power, while the terminal two methods build abstraction layers over the native methods. Other than this, it is too possible to build custom ETL tools based on the Redshift native functionality. AWS'southward own services have some limitations when it comes to data sources outside the AWS ecosystem. All of this comes at the cost of fourth dimension and precious engineering science resource.
Hevo Data provides an Automated No-code Information Pipeline that empowers you to overcome the above-mentioned limitations. You can leverage Hevo to seamlessly transfer data from diverse sources to Redshift in real-fourth dimension without writing a single line of code. Hevo's Data Pipeline enriches your data and manages the transfer process in a fully automatic and secure manner. Hevo caters to 100+ data sources (including 40+ free sources) and tin can directly transfer data to Information Warehouses, Business Intelligence Tools, or any other destination of your choice in a hassle-free fashion. It will brand your life easier and make data migration hassle-free.
Visit our Website to Explore Hevo
Want to take Hevo for a spin? Sign up for a 14-mean solar day gratis trial and experience the feature-rich Hevo suite firsthand.
What are your thoughts on moving data from your sources to Redshift? Let us know in the comments.
Source: https://hevodata.com/blog/loading-data-to-redshift/
0 Response to "R Bloggers Bulk Upload to Redshift ?"
Post a Comment